常见的网站/页面没有被谷歌收录的9个原因(附解决方案+思维图)

我在上一篇关于谷歌技术SEO的文章中分享了一段这样的经历:在发现一个几乎没有热度和页面权威度的网页没有被收录后,我通过把网页加入到XML Sitemap中这样一个简单的动作,在两天内实现了被收录。
过去也被不少人问过:新网页没有被收录,和旧页面做了优化后迟迟不见搜索引擎同步更新之类的问题,所以在这篇文章,就来说说常见的导致网页不被Google收录的原因和如何去解决它。
内容有点多,所以我用思维图整理了这个话题的重点,方便大家快速 、系统地进行了解:
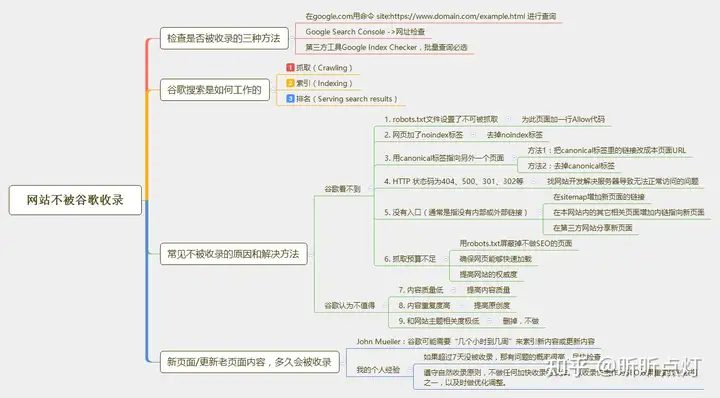
一. 检查网站是否被收录的三种方法
没有收录,就没有排名可言,具体逻辑在后面的第二大点关于谷歌搜索引擎是如何工作的有讲到。
一般我们发现页面没有SEO排名和流量,就会第一时间去检查该页面是否被谷歌收录了。我常用的三种检查收录的方法:
- site命令
在http://google.com用命令 site:https://www.domain.com/example.html 进行搜索查询。如果有返回正确结果,就代表已经收录了。
注意:site指令不会显示所有相关结果。如果你发现存在site命令没有返回正确结果但是Google Search Console却显示已编入索引的情况,可以参考我在另外一篇文章“用site命令查到页面没被收录/索引页数少于谷歌网站管理员工具中报告的页数,怎么办?”中关于这个问题的优化思路。
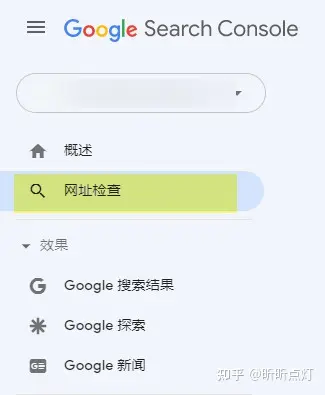
2. Google Search Console的网址检查工具。见下图:
3. 第三方Google索引检查工具。
前面两种方式都只能每次查询一个页面,用第三方工具的好处是可以实现批量查询。Google一下“Google Index Checker”,可以找到很多在线检查收录的工具。
如果不幸地,你通过以上的方式查出你的页面没有被收录,那希望下面的解决方案能够帮助到你实现页面被Google收录。
二. 谷歌搜索引擎是如何进行页面抓取、索引和排名的
知乎上也有不少关于网站内容没有被收录问题的解答,但是很少会讲到搜索引擎是如何工作的。我认为大家很有必要知道,因为当你通过学习搜索引擎工作原理去理解了网页不被收录的本质,你就拥有了能够快速地化解所有不被收录问题的能力。
让网页出现在谷歌搜索结果中需要经历三个阶段:
阶段1:抓取(Crawling)
抓取也经常被称为“爬行”。谷歌会使用一种自动程序从互联网上发现各类网页,并下载其中的文本、图片和视频,这个程序经常被称作“蜘蛛”、“机器人”或“爬虫”(都是指同一个东西)。
推广经常会看到的两种谷歌蜘蛛:应用在SEO工作上的Googlebot,和应用在广告工作上的GoogleAdsBot。
为了让你的内容显示在 Google 搜索上,必须首先确保你的网站可以被 Google 的 Googlebot 抓取工具抓到。
阶段2:索引(Indexing)
Google 会分析网页上的文本、图片和视频文件,并将信息存储在大型数据库 Google 索引中。
不是所有被抓取的页面都被会索引。
阶段3:呈现搜索结果(Serving search results)
当用户在 Google 中搜索时,Google 会返回与用户查询相关的信息。
不是所有被索引的页面都会有排名。
基于以上,如果你的网站没有被收录,那原因只会是下面两点:
- 谷歌看不到
- 谷歌认为不值得
三. 常见的网站/网页不被谷歌收录的原因和解决方法
首先来说说因为谷歌看不到从而无法被抓取的6种常见的情况:
1. robots.txt设置了不可被抓取
robots文件告诉了搜索引擎要抓取哪些网页和不要抓取哪些网页。
检查你的robots文件中disallow部分代码,看看不被收录的网页是不是触发了disallow规则。
比如我们来看anker的robots.txt, 它禁止了谷歌去爬URL中带有/coming-soon的网页。也就是说,如果你的网页URL是https://www.anker.com/coming-soon/power-adapter,那通常(非绝对)谷歌就不会去爬它。
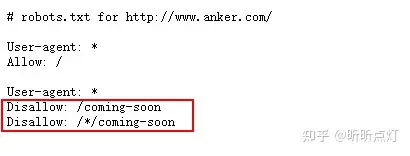
最快的解决方法是在robots文件中加一行Allow代码:
Allow: https://www.anker.com/coming-soon/power-adapter(要谷歌被爬行的网址)
2. 网页HTML代码加了noindex标签
noindex标签的作用是告诉搜索引擎不要去索引该页面。
检查方法:页面右击->查看网页源代码->搜“noindex”, 如果你发现有以下这行代码:
<meta name="robots" content="noindex,nofollow" />
那你要做的就是去掉这行代码。
3. canonical标签指向另外一个网页
canonical标签是为了解决网址规范化问题,告诉搜索引擎那个网址才是最重要的。
网页可以不带canonical标签。我发现很多网站的页面都会带上canonical标签, 链接指向本页面;如果链接指向非本页面, 那谷歌很多时候(非绝对)就不会抓取该页面。
检查方法:页面右击->查看网页源代码->搜“canonical”,如果canonical标签里的链接不是本页面的URL,那你要做的就是把链接改成本页面的URL,或者直接去掉canonical这行代码。
4. HTTP 状态码为404、500、301、302
托管站点的服务器在响应搜索蜘蛛爬虫发出的请求时会生成HTTP状态码。
我们经常遇到的会造成搜索爬虫无法抓取页面的HTTP状态码是404、500、301和302。
如果打开网页,发现返回了以上状态码提示,无法访问,那你要做的是去找网站开发人员去处理。
正常能让搜索引擎爬虫和用户访问的页面的状态码是200。
5. 没有入口(通常是指没有内部或外部链接)
蜘蛛在工作时通常从一个 URL 开始,然后从顺着爬到其它URL。如果你的页面是孤立的,那就很难被蜘蛛爬到。因此,我们需要给搜索引擎蜘蛛一个引导。
以下是三种简单又快速增加入口的方式:
- 把链接加入到XML sitemap。
- 找到自己网站内和此页面内容有相关联的网页,增加一个指向该页面的内链。
- 在第三方网站分享链接,比如Twitter,Facebook和一些RSS网站。
6. 抓取预算不足
谷歌有数千台机器来运行蜘蛛,但有一百万个网站等待被抓取。因此,每个蜘蛛到达你的网站时都会有预算,也就是它们可以在你网站花费的资源数量是有限的。
以下三种方法都可以提高抓取预算:
- 用robots.txt屏蔽掉不做SEO、也不会影响整站SEO排名的页面。
- 确保网页能够快速加载。
- 提高网站的权威度。
以上就是常见的在搜索引擎第一阶段工作时就遇到了阻碍导致到无法正常进入索引的情景。
接下来讲讲因为谷歌觉得页面质量不行从而不值得去收录的三种常见情况。
7. 内容质量低
举个极端的例子:一个页面只有一行话,这种内容极度薄弱的页面, 是几乎不可能通过谷歌的收录。
没什么捷径可走,就是提高页面内容的质量。
8. 内容重复度高
举个常见的例子 :你的网站转载了一篇由行业内名人撰写的非常专业的文章,而且这篇文章也被很多其它网站转载了,谷歌就会认为这些网络上大量重复的内容对用户来说是没有价值的,故就不会去收录。
没什么捷径可走+1,你要做的就是去提高内容的原创度。
9. 和网站主题相关度极低
打个比方,你运营的是一个专业卖衣服的网站,突然增加一个关于教人如何做金融投资的页面,主题差异相当大。这个时候,谷歌就很可能会因为相关度不高而拒绝收录。
对于这种情况,我的建议是直接删掉该页面。如果真的要做,至少要放到是在同一个行业性质的网站。
四. 新页面/更新老页面内容,多久会被收录
来自谷歌的John Mueller说,谷歌可能需要“几个小时到几周”来索引新内容或更新内容。
也就是说,如果你发现一天过去了,新页面还没有被收录,不用着急,先按照上面的方法快速检查一遍。没有发现问题的话,就再耐心等等。
那我自己运营的独立站的情况是:新页面和老页面的更新,通常被收录所需时间在30分钟到3天。如果新页面的内容主题跟网站的主题相关度很高、推广的产品是最近流量和转化非常不错的品类、在过去一段时间关于该话题的内容也更新得比较频繁,同时内容质量和原创度也高, 那收录会非常快,一般半个小时就能看到被收录了。
也有过需要3天左右才被收录的新页面,通常发生在网站新开发的品类。在这里想特别分享我自己的一个小心得:以前新页面超过1天没有被收录,我就会很着急地提交站点地图,把链接分享到外部网站;而现在我是遵循自然收录原则,不做任何加快收录的动作。这样做的原因是, 我发现收录得慢的网页,通常在收录后排名和流量效果都不会特别理想,因此收录快慢就能够作为我去预判该页面SEO效果的一个重要依据。基于预判,如果在页面上线后的半个月效果不好,那我就会迅速采取提高内容质量和布局更多此话题内容之类的动作,来提升Google SEO排名。
要是新页面在上线一周后还是没有被收录,我认为不需要遵守John Mueller所说的标准再等上几周。除非你的网站或者新页面的内容非常垃圾,否则肯定是哪里出了问题,还是尽早排查为好。
 返回首页
返回首页
 谷歌SEO学习资料
谷歌SEO学习资料